Boa v0.9: measureme & optimisations
Hello World!
Boa is an experimental Javascript lexer, parser and compiler written in Rust. It has support for some of the language, can be embedded in Rust projects fairly easily and also used from the command line.
Boa also exists to serve as a Rust implementation of the EcmaScript specification, there will be areas where we can utilise Rust and its fantastic ecosystem to make a fast, concurrent and safe engine.
Today we're pleased to announce our latest release, version 0.9.
v0.9 is by far the biggest release we've had since Boa began. You can find the full changes from the changelog. The milestone behind this version was further optimisation and an increase in new features. We can show you how we can identify areas that can be optimised.
Better tooling for profiling
Boa became the first Rust project to make use of measureme, a profiling tool built from the ground up for Rust. This was only used by the Rust team themselves to profile the compiler. We managed to work with the compiler team to get the framework in a good enough state to be used by other projects too, and in this release, we gave it a try.
Measure me lets you profile various areas of your choosing, then you can generate a trace file which can be loaded into Chromium or various other tools for analysis. We took it for a spin (which you'll see in Object Specialization).
Below is an example of our trace, this is using a measureme tool called summarize
+----------------------------+-----------+-----------------+----------+------------+
| Item | Self time | % of total time | Time | Item count |
+----------------------------+-----------+-----------------+----------+------------+
| From<Object> | 1.04ms | 14.776 | 1.04ms | 146 |
+----------------------------+-----------+-----------------+----------+------------+
| new_object | 356.50µs | 5.082 | 533.50µs | 18 |
+----------------------------+-----------+-----------------+----------+------------+
| create_instrinsics | 263.50µs | 3.756 | 6.38ms | 1 |
+----------------------------+-----------+-----------------+----------+------------+
| make_builtin_fn: toString | 218.50µs | 3.114 | 290.50µs | 12 |
+----------------------------+-----------+-----------------+----------+------------+
| String | 81.60µs | 1.163 | 961.60µs | 1 |
+----------------------------+-----------+-----------------+----------+------------+
You can read more about Rust's usage of measureme here.
Object Specialization
In JavaScript internal metadata for objects are stored in internal slots. In Boa we stored internal slots as a hashmap tied to the object, with the keys being strings and the values as JSValues. This meant we needed to constantly unwrap them into a Rust primitive to access the data. Secondly we were restricted as to what type of data we could put in internal slots. For example, lets say we want to implement Set by using the native HashSet as a backing store, this would not be possible.
By changing how internal data is handled for some of our builtin objects and removing a whole bunch of redundant access checks, we managed to speed up the interpreter.
Boa would spend a significant amount of time converting back and forth between JS Values and primitive values. We found a huge amount of time was spent in Value::set_field before any code had even been executed. set_field was slow due to the amount of updating of internal slots as part of setting up. Here you can see realm creation takes roughly 60ms (dev build).
We use Crox to convert our measureme data into a format Chrome's performance tab understands
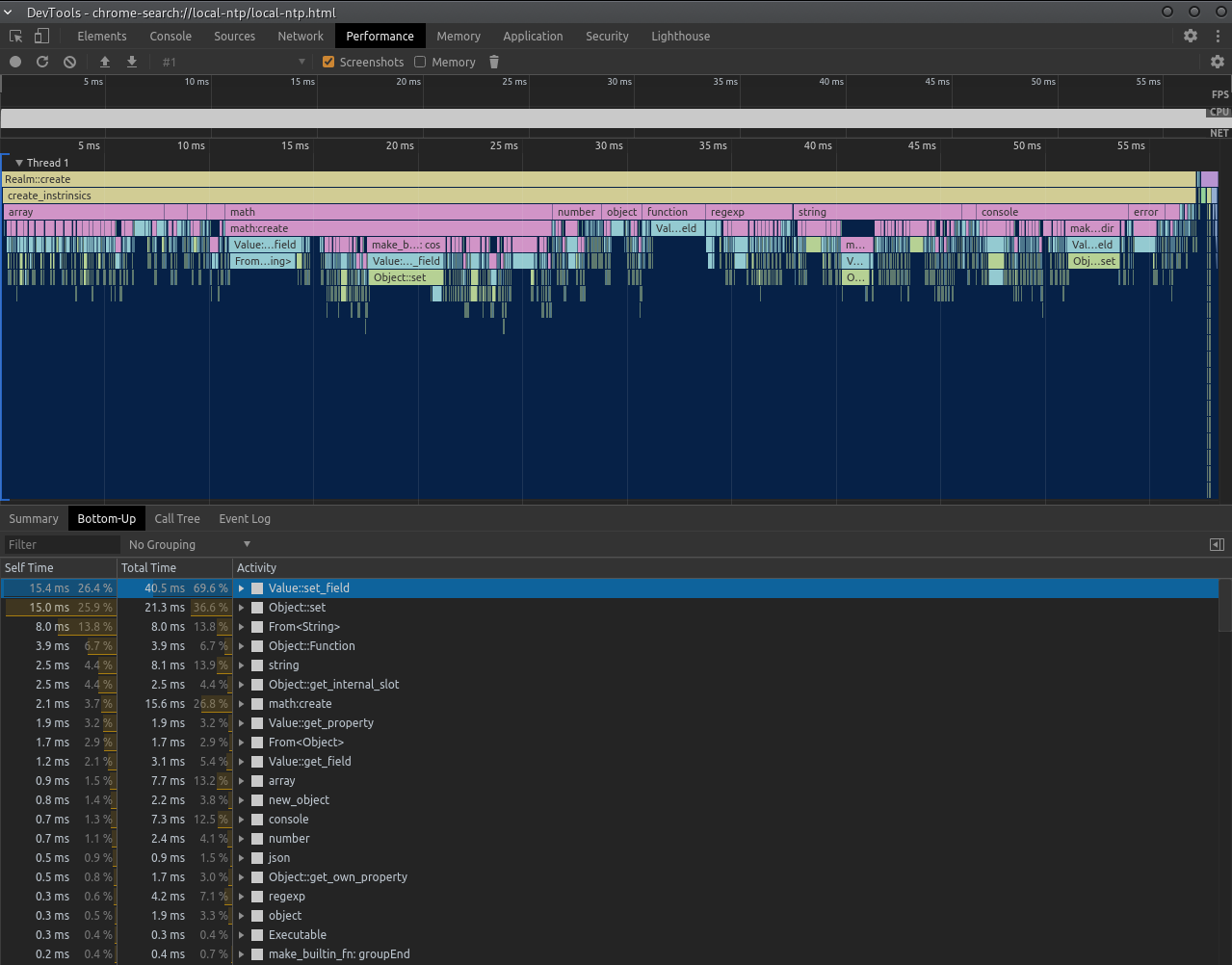
We refactored many builtins to hold an ObjectData enum variant instead, some of which can hold a value for the type also.
This can be used to both identify objects and to use their internal data.
Here is an example of our enum.
/// Defines the different types of objects.
#[derive(Debug, Trace, Finalize, Clone)]
pub enum ObjectData {
Array,
BigInt(RcBigInt),
Boolean(bool),
Function(Function),
String(RcString),
Number(f64),
Symbol(RcSymbol),
Error,
Ordinary,
}
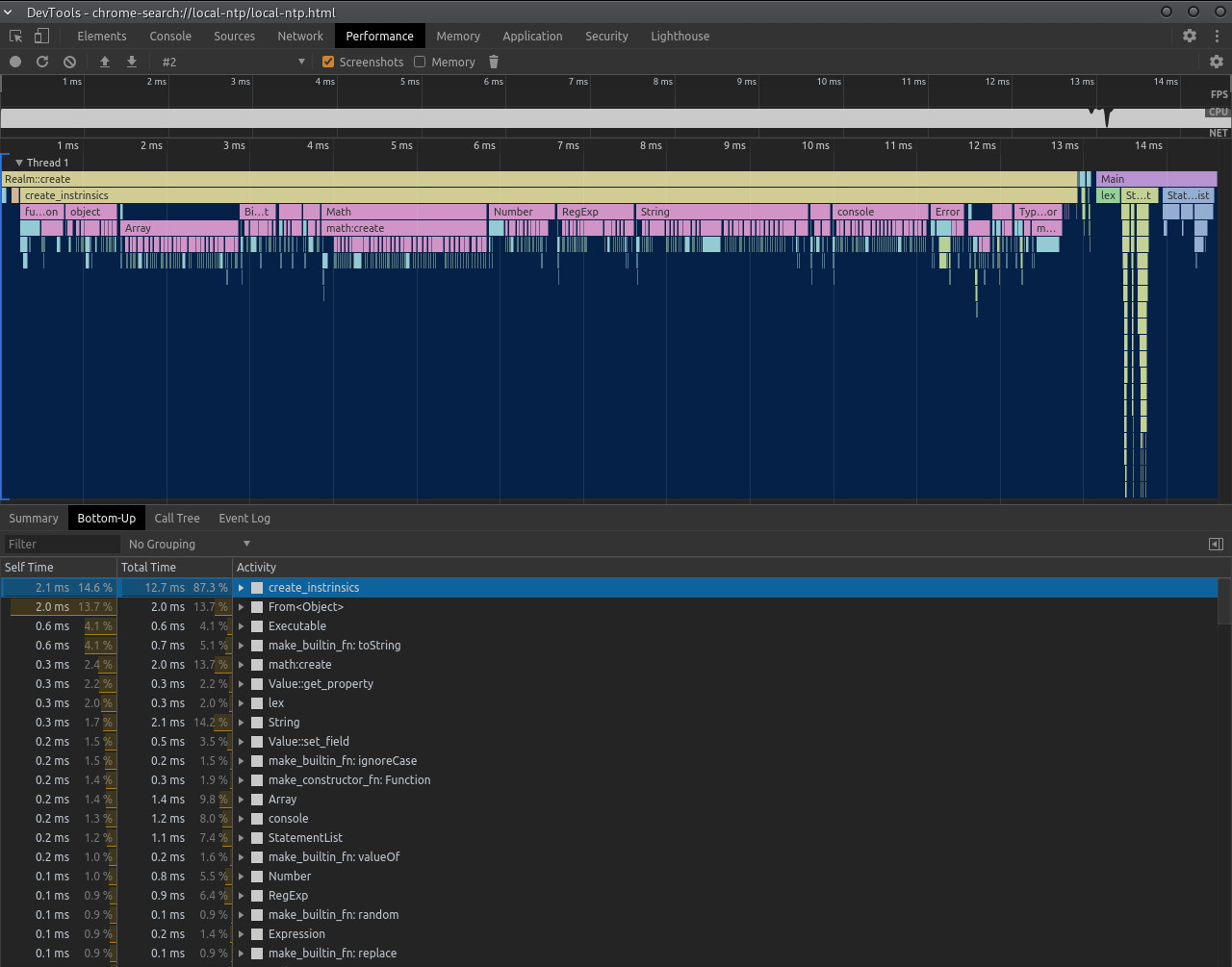
This gave us a 70% speedup and reduced startup time by well over half. The realm::create function now runs in 13ms instead of 60ms.
Optimised Type Comparisons
If you've ever called typeof in JavaScript, you get a string value describing the primitive type of it's argument. Boa was doing the same internally for comparing (using the "get_type()" call), however getting the string value from each primitive then comparing them is not very performant.
Now, thanks to @Lan2u we have a rust Type enum which makes comparing more efficient and on average brings another 8% performance boost.
JSValue Refactor
We have completely refactored how JavaScript values are stored.
#498 makes values more lightweight by only GC'ing objects and not the primitives. The primitive scalar values are just Rust primitives which implement the Copy trait, so the overhead of moving these around is much lower.
By decoupling our Value types and GC types we have brought our Value size from 40 bytes => 24 bytes and an 80% reduction in arithmetic operations!
Parser rebuild, better code organisation
Boa was predominantly 3 files. The lexer, parser and interpreter.
The naive implementation of the parser was a single file which had a long match expression for tokens and went through every token figuring out what to do. This did the job but became unmaintainable when adding new features.
We have been breaking the parser up into separate modules, which represent various expressions and statements that conform to the specification. (more about this in a future post).
After all the fixes in this release we've seen on average a 70% improvement, we still have areas where we plan to improve. We are currently rebuilding the lexer so it is more broken up like the parser and interpreter, we will blog about this soon in future.
Roadmap
How much of the specification is covered?
Our next milestone is to tidy up the lexer so it takes into account goal symbols then we plan to start running Test 262, the official ECMAScript Test Suite. It has a lot of tests (over 29272 test files) and will tell us in detail which parts of the specification need work.
There are also large items like classes which are still not covered, however, these should now be easier to implement with parsing broken up.
Public API
#445 looks to improve the public API too so Rust projects can interactive with Boa more easily.
It should be possible today to just use the lexer, parser or the whole execution path.
We hope to add more detail in future on how some parts of Boa work, make sure you stay tuned for any future posts!